現状のてつわんこシステム(ラーシェの内側)はこんな感じです。
文章で書いてもいまいち要領を得ないので、とりあえず図で示します。

他であまりやってないのは、「自身のこれまでの会話ログの要約」も生成の文脈に含めてることと、内省を促すループの部分でしょうか。
ここまでやっても、なんかまだ足りないなあって気がするので、思い出したころにまた更新しようと思います。
現状のてつわんこシステム(ラーシェの内側)はこんな感じです。
文章で書いてもいまいち要領を得ないので、とりあえず図で示します。
他であまりやってないのは、「自身のこれまでの会話ログの要約」も生成の文脈に含めてることと、内省を促すループの部分でしょうか。
ここまでやっても、なんかまだ足りないなあって気がするので、思い出したころにまた更新しようと思います。
OpenAI o1というなんか新しいやつが出ました。
今までの評価ループをぐるぐる回して試行錯誤させるプロセスをアルゴリズム的に組んでいた部分を、代わりに自分自身で行えるようトレーニングしたモデルってことですかね。
たぶん普通の質問したら、今までとたいして変わらない回答が返ってきて、「処理が遅いだけやん!」って失望してる人も割と居るんじゃないかと思いますが、難しい疑問を簡単な問い合わせで解決できる方法の一つとしては有力でしょう。
あと、これはまだはじまりにすぎないって感じなので、最初のテスト版を触って失望するのはまだ早いかなぁと。
真似事レベルなら、プロンプトの工夫+再評価させるループを組むコードで、できると思います。
一度考えをユーザーから見えない部分で繰り返しリファインしてまとめさせてから、その結果を使って再度発言させるって形にすれば、どうにかなりそうですよね。
OpenAI o1は論理面に絞って推論させてるので、ぱっと見地味でつまらない、っていう評価をする人も居ると思うんですけど、同様なことを人間の心の理論に沿った方向で推論させる(ユーザーが今抱いている感情は何かとか、過去ログからユーザーの発言に至る背景を探せとか)なら、より人っぽい出力をさせるという方向での改善ができると思います。
めんどくさいからだれかやって。
本日、だいぶ長い間放置していた、メインサーバの新サーバへの移行作業を決行しました。
年払いの利用期間の区切りが7月末だった、というのもありますが…
これで性能が大きく改善した…わけではなくて、正直体感で気づくような違いは何もないと思うんですが、たまにOSインストールからごっそりリフレッシュ作業を行うのは悪くはないと思うのです。たぶん。
# 受け側 nc -l ポート | pv | tar xz -C /ディレクトリ # 送り側 tar czf - -C /ディレクトリ 転送したいディレクトリ名 | pv | nc サーバIP ポート # ToDo シンボリックリンクの扱いのオプションをtarに加えたほうがいいかも # あと文字コードエラーになりやすいので大量のファイルを正確にコピーするならrsyncで
100%興味本位で実用性皆無ではあるのですが、液晶パネルがぶっ壊れたまま放置していたPixel 5aを、ふと自前で修理してみようと思い立ち、iFixItで修理キットを発注しました。
修理説明とキットの購入はこちらから。
で、支払いも済ませて「出荷したよ!」という通知も来たのですが、
USPS Tracking Number : EPG????????????
という謎のEPGではじまる追跡番号を投げ込まれて、それUSPSの番号ちゃうやろ!*1どうやって追跡すんねん!とツッコミを入れるハメに。
もちろんUSPSのサイトでは「お前の出荷番号は無効だ」と言われる始末。
で、頭のEPGに着目して、そういう略称の国際小包サービスがないかと調べたら…ありました。
ePost Globalというサービスだそうです。
https://epostglobalshipping.com/
追跡サービスはこっち。
入力したら、6/2に航空機に載ったというところまでわかりましたし、本来のUSPSの番号も判明しました。
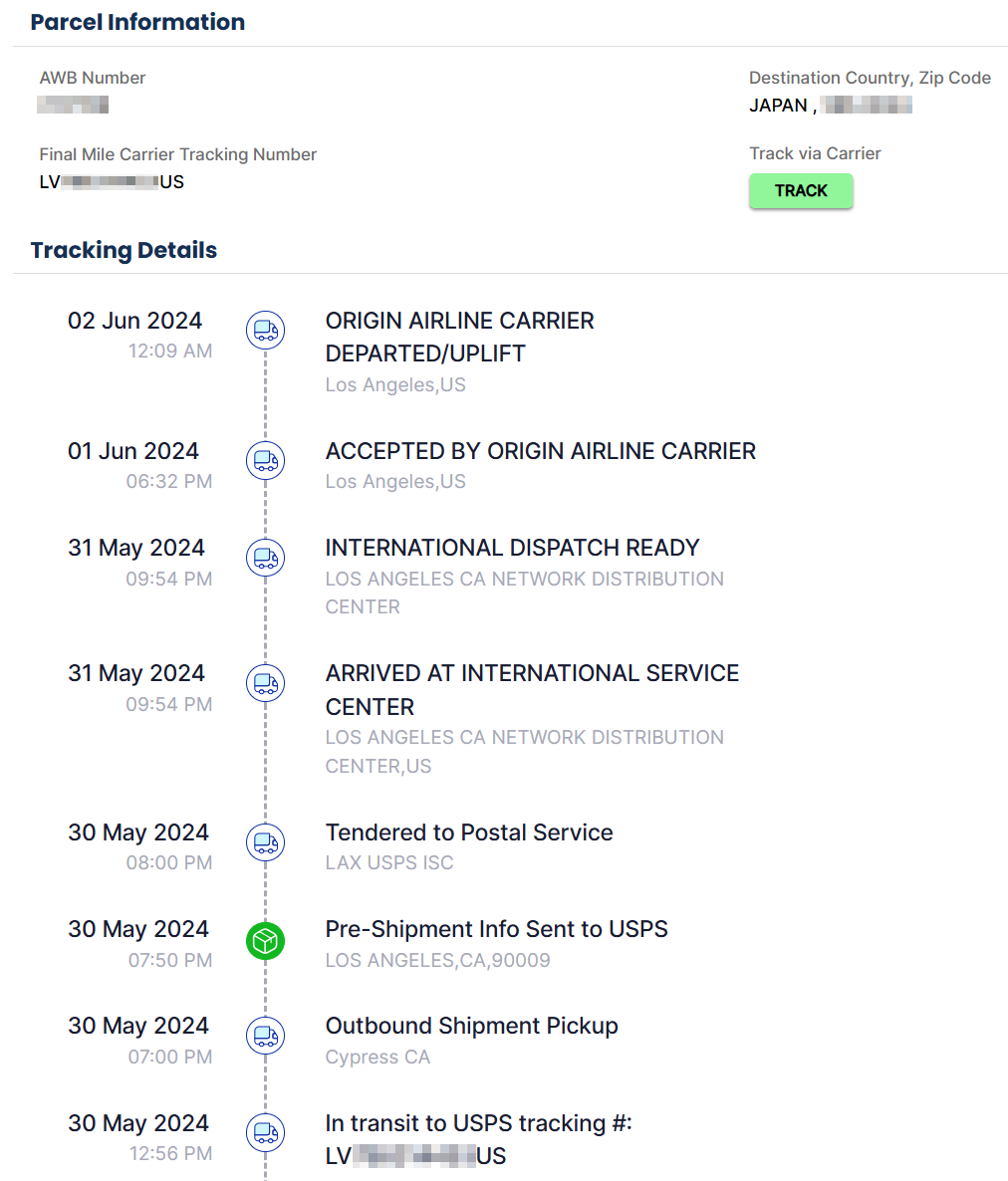
…ところで、いつ着くんでしょうね?このまま更新されないとかいう流れの嫌な予感が…
言いたいことはタイトルの通りで終わっちゃいました。よろしくお願いします。
まず、理屈上では10GBASE-Tは帯域幅400MHzを要求するので、500MHzまで対応するCAT6Aがふつうは必要です。終わり。
…そんなんわかっとるわいって感じですね。じゃあ現実問題としてどの程度の影響があるのでしょうか。
会社のネットワーク環境の見直しで、最近じわじわと10Gbps化を進めているのですが、昔敷設したケーブルの中で、30mのCAT5eケーブルがあり、規格上は当然10Gbpsを通せないので、ネックになっていました。
ケーブルを引き直すのもめんどくさいし、とりあえずワンチャン動くかもしれないからつないでみようってことで、その両端に10Gbps対応のL2スイッチをつないだら、なんとリンクアップしちゃって、問題なくパケットも通ったんですよね。なんでやねん。
動いちゃったからこれでいいや~と思っていたんですが、げんじつはきびしい。
片方のL2スイッチのパケット統計画面を見てみたら、他の似たようなケーブル長の区間と比べて、3桁4桁(100~1000倍)増えた、チェックサムエラーや符号化エラーの数値が出ていました。これあかんやつや。
仕方ないので、頑張ってCAT6Aのケーブルを買って引き直したら、まともに戻りました。そらそうだ。
ちもろぐさんで試していたのは下記の通りでした。
CAT5eのベンチマーク結果の「リンクアップするけど微妙にグラフがばたついている」のが、パケットエラーによる破棄が多く発生している影響を可視化できている感じかなあと思います。6と6Aで大差ないのも一緒ですね。
CAT7とか8とかはとりあえず要らないのも同意…